



字数原因,链接上篇:提示词入门教程·上篇:《元素同典:确实不完全科学的魔导书》
除此之外还可以尝试其它不是 Prompt S/R 的选项,比如用 Seed 比较不同种子,用 Step 比较不同步数,诸如此类。更深一步则是进行多组分析,以及通过排列组合或其它统计方法来确定多个要素之间的作用等。
如果不做定性/定量分析,那么可能将持续沉浸在知其然不知其所以然的程度,也可能仅满足于妙手偶得而产生相对片面的理解。
始终记得赛博魔法的本质是科学。
力大砖飞,超级步数出奇迹
【此部分现已不建议参考】
在上文基础部分,笔者推荐在简单情况下将步数设为不算高的数值,因为在简单画面的情况下步数过高也似乎没有什么好细化的。
但要是在一个细节稍复杂的场景里把步数做得很高很高那么会发生什么?

(masterpiece), best quality, 1 girl, red eyes, white hair, white gown, forest, blue sky, cloud, sun, sunlight
不难发现画面的确变得精细了。空中的云变得更真实,人物背景从简单的树林过度到有层次的树林再变成土丘上的树林。当然,最显著的还是人物体态的变化——虽然手部的举起与放下之间似乎无法分辨出什么规律,但似乎也有着被进一步细化的情况。总得来说,简略与详细都有独到之处,是萝卜白菜各有所爱的程度,也难怪大多数情况下认为步数过高没有特别的收益...
等等。我们刚刚是不是提到了手?

(masterpiece), best quality, 1 girl, red eyes, white hair, white gown, hands
人物整体在 20 步就已经奠定完毕,后续步数没有显著改动,但是手却不一样。20 步的手就是一团错位的麻花,40 步虽然显得扭曲但是已经能和胳膊接上,60 步除了部分手指以外都做得不错,80 步更是在此基础上进一步降低了融化程度。虽然 80 步的手也没有达到理想中的效果,但是不难发现高步数下,人物手部的表现有着明显提升。
这个结论在绝大多数情况都适用——如果想要特别细化手部表现力,那么请忽略上述步数建议,将步数拉到 80 甚至更高。而进一步推论是,高步数在合适 prompt 的引导下,对于大多数细小、解构复杂的区块都效果拔群,只是对于大块非复杂场景方面的营造存在显著边际效应。
魔法公式入门
首先,prompt 并不可以随意堆积,不是越多越好。
模型读取 promot 有着明确的先后顺序,这体现为理解顺序的不同。比如又一个著名的“少女与壶”试验所展示的:

masterpiece, 1 girl, red eyes, white hair, blue pot

masterpiece, blue pot, 1 girl, red eyes, white hair

masterpiece, blue pot, ((1 girl)), red eyes, white hair
masterpiece, blue pot, ((1 girl)), red eyes, white hair
在种子相同且其它参数也完全相同的情况下,仅仅是颠倒了 1 girl 与 blue pot 的顺序,构图就产生了极大的变化。
不难发现,1 girl 在前的情况下,画面围绕着人物展开,blue pot 体现为环绕着人物的场景物件。而 blue pot 在前的情况下,画面围绕着盆展开,人物反而退出了画面中心,甚至哪怕加大 1 girl 权重也无法让人物比盆在画面中更重要。
这其中的原理不适合在入门魔导书中详细解释,但可以提供启发 —— prompt 的顺序将影响画面的组织方式,越靠前的 prompt 对构图的影响越“重”,而越靠后的则往往会成为靠前 prompt 的点缀或附加物。顺序对于构图的影响在大多数情况下甚至大于权重的影响。
对于SD1.5来说可以使用早期法典时期搞出来的三段式提示词,
前缀+需要重点突出的物件/背景+人+人物特征/元素+人物动态+服饰整体+服饰细节元素+大背景+背景元素+光照效果+画风滤镜+微小辅助元素+后缀
而到了SDXL,请根据模型作者所标注的提示词顺序来进行编辑,有些人会在使用SDXL模型的时候继续沿用SD1.5的习惯格式而不用模型卡的推荐设置,这会导致出图达不到预期。请记住:在SDXL的模型中,不存在“三段式”或者所谓“4W1H”这种提示词的固定格式,一切需要按照模型卡来
当然出图达不到预期这只是现象,这实际上只是模型作者在训练的时候使用的标注格式不同。
比如kohakuXL就是使用的如下:
<|special|>, <|characters|>, <|copyrights|>, <|artist|>, <|general|>, <|quality|>, <|meta|>, <|rating|>
那么我在使用其他的tag格式的时候,出图就很难达到预期(有些效果出不来,有些效果乱出)。
下面是另外两个模型的tag格式。
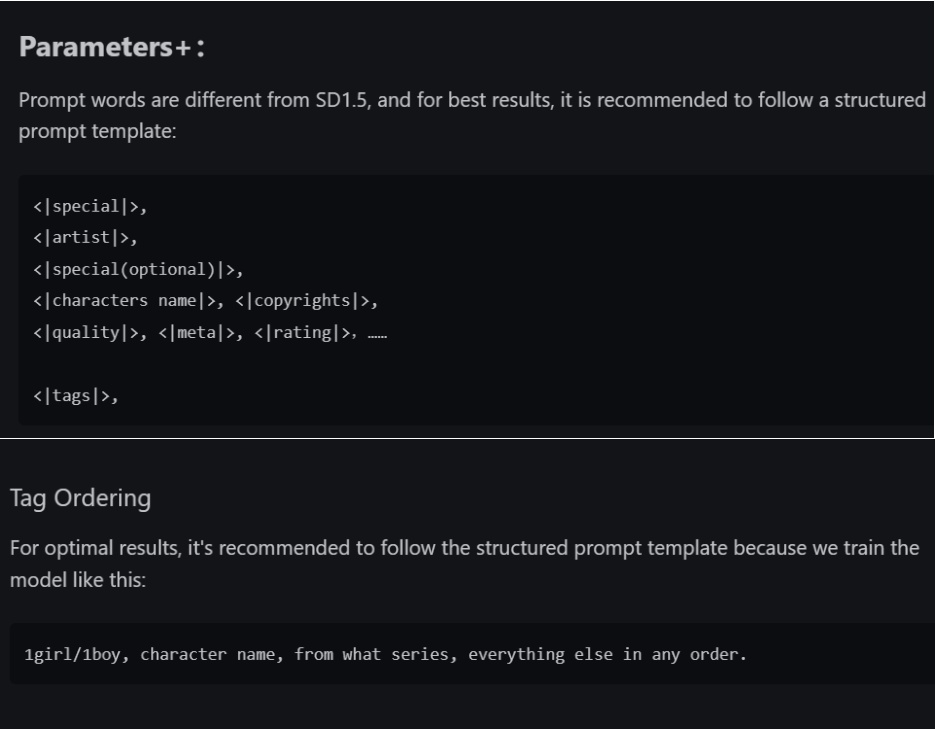
而最近讨论度较高的ArtiWaifu Diffusion,则是有着更严格的格式限制

奏咒术一曲蔌蔌,浩渺无声
我曾见过,你们新魔法师永不会相信的东西。在⚪山上面堆积着的咒语,在论文式长文中崩坏的结构。然而所有这些都将随时光而去,就像咒语中的音节。
一个词要见另一个词并不容易
掌握上文的顺序公式,其实也只是开始中的开始。
大致顺序固然很重要,但它太过大致了。不难发现实际应用并不是那么简单的“后者叠加在前者之上”关系,与理想中的一一对应式叠加相差甚远。
既然现实与理想不符合,那么是时候看看为什么会这样了。
试一下吧。假设现在我们需要生成一个在有着许多花的平原里的二次元美少女,这个美少女没有花发饰。假设我们同时还需要在画面中生成特别特别多的花,那么就应该给 flower 一个比较高的权重,比如 1.35。

masterpiece, 1 girl, blue eyes, white hair, (flower:1.35), in field, blue sky, sun, cloud
情况不符合没有花发饰的预期。事实上不仅仅是这一张图,上述咒语生成的大多数图片都会让人物带上发花装饰。这不难理解,flower 的权重过大,导致它在画面中倾向于占有更大的比率、更强的表现,迫使元素与元素被错误地绑定了——是与上文提及的元素不绑定相反的情况。
降低 flower 的权重可以一定程度上解决问题,但在实际应用中,很可能出现某个物件必须要有较高权重才能达成预期效果的情况,或者权重已经非常低了依然出现这种尴尬情况。既然不可以降低权重,那还能怎么办呢?
两倍的长度,一半的意义
那么有没有办法让花也不出现在衣服上?
如果继续维持权重不可改变的限制,也不应用其它技巧,那么最简单的思考方向是让 flower 和一切形容人物的咒语部分都拉开更远的距离,加上一些用于描绘其它画面元素的词就能做到。但如果情况要求不应该为画面引入新元素,就不能这么做。
注意到此时加入词的目的仅仅是为了拉开两个词的距离。但首先(虽然其实已经有些迟了),我们应当定义一下什么是“距离”。
这个数字会出现在 WEB-UI 的负面咒语输入框右上角。它严格的叫法其实是这段咒语“生成的 向量/token 数”,但作为不需要深究法杖炼成原理、只需要掌握应用赛博魔法师,我们只需要清楚它代表一段咒语的“物量”就行了。(在实际使用中clip的有效token数就是75,当token数量大于75的时候webui会采用clip拼接的方式处理提示词,也就是绘本分在多段clip里,我们这里的定义只要两个词跨过75、150、225……这几个点,那么就说明这两个词“距离远”)
物量可以用来衡量咒语的长度,而两个词之间的间隔物量数就是它们的距离。
新加入的词本身应该是尽可能无意义的,并且在此基础上多占用一些物量来产生距离骗过自然语言处理部分,我们将这样的词称之为占位词。诸如 what which that 等在自然语言中无明显指代对象的词都一定程度上可以用作占位词,所以当你在一些老旧的提示词中找到了诸如“//////////”这种无异于的字符,不用怀疑这就是占位词。现在我们有更好的方式来强行进行clip分段,这就是BREAK这个词的作用


masterpiece, 1 girl, blue eyes, white hair, BREAK, in field, blue sky, sun, cloud, BREAK, (flower:1.35)
花彻底从人物身上移开了。虽然 AI 的不稳定性让它依然有作为服饰或发花出现的情况,但概率被进一步降低了。
占位词可以用于进一步调整词与词的距离,从而加强切割某些不希望绑定在一起的元素,是“元素污染”情况的又一有力解决方案。这就是“最简发花”试验。
词与词之间也不能毫无节制地加入占位词来降低关系。根据测试,词与词之间的关联度似乎和距离有着一定程度上的反比例关系或保底关联度,因此加入过多占位词不会有额外的好处,适量添加即可。当然占位词现在已经不再使用了,直接用BREAK就行。
而更深入的原因还可以是,WEB-UI 对于词的分割是每 75 物量一组,使用占位词来略过接近 75 物量的部分,可以避免连续的描述状态被切割。连续的描述状态被切割会导致无法预期的糟糕后果,所以应当避免。
赛博音节会梦见电子杖心吗
从 SD 框架的自然语言处理部分可以提取出关联性和占位词的应用,而从训练集则还可以提取出其它知识。
如上文所述,NAI 的重要训练来源是 danbooru.donmai.us,而其它绝大多数模型也或多或少与这个网站的素材有所关联。如果各位赛博魔法师们真的前去调查了它的 tag 标识,那么不难发现一些有趣的现象——许多 tag 有着逻辑上合理的“前置”关系,比如存在 sword 这个 tag 的作品往往还存在 weapon 这个 tag、存在 sleeves past finger 这个 tag 的作品往往还存在 sleeve past wrists 这个 tag。
这样在训练集中往往共存且有强关联的 tag,最终会让模型处理包含它的咒语时产生一层联想关系。
不过上述联想关系似乎不够令人感兴趣,毕竟这些联想的双方都是同一类型,哪怕 sword 联想了 weapon 也只是无伤大雅。那么是否存在不同类型的联想呢?
答案是存在的:

masterpiece, 1 girl, blue eyes, white hair, white dress, dynamic, full body, simple background

masterpiece, 1 girl, blue eyes, white hair, white dress, (flat chest), dynamic, full body, simple background
不难发现 flat chest 除了影响人物的胸部大小之外还影响了人物的头身比,让人物的身高看上去如同儿童身高一般,如果调整画布为长画布还会更明显。因此称 flat chest 与 child 有着联想关系。人物胸部大小和身高是不同的两个类型,两个看似类型完全不同的词也可以产生联想关系。对 flat chest 加大权重,会让这种联想关系会表现地更为突出。
它的原理和上述同类型的联想一样,都是训练来源导致的。平胸美少女和儿童身高在同一个作品内出现的概率非常大,而模型训练的时候又没有很好的进行区分。这种联想关系在社区中曾被称为“零级污染”。除此之外最为常见的还是再CF3模型里,rain提示词必定会出现伞这一现象。
掌握了联想关系的知识之后的用途仅限于灵活应用它来更准确地营造画面,联想词之间极易互相强化,进而提高画面的稳定性。例如给人物稳定添加一把剑的最好做法不是仅加上 sword,而是加上 weapon, sword。同理,其他存在强联想且希望出现的元素也可以同时在咒语内连续出现。
为了在画面内取消两个词之间的联想,最简单但不一定有效的做法是将被联想词写入负面咒语并加上较高权重。如果没有效果,那么不妨试一试在咒语内加上被联想词的对立面,比如用 aged up 对抗 flat chest 对于 child 的强联想。
向着魔导科学的最根源
嘟嘟嘟——魔导列车启动啦!请各位乘客注意安全,系好安全带,防止双轨漂移时被甩出车gdjhgvdjkhgvdfhdgvjfhhd
重新解析咒语构成
既然上文补充了标准顺序公式遗漏的细节,那现在能不能让它再给力一点?

当然能!
无数个疑问都指向了由词性分析与联想关系理论所引发的新思考方式。既然用于描述一个元素的词与用于描述另一个元素的词之间的距离会影响叠加的程度,那么不如直接将一切元素与其对应描述词的组合都抽象为一个“物”。人是一个物,人身上的一些小挂饰也是一个物(无论这个挂饰的数量是多少),背景里的建筑也是一个物,诸如此类。物!
每个物都有能力成为主要描绘对象。如果是人,那么可以是人的立绘或特写,如果是挂饰,可以是它的展览模样,甚至背景大建筑也可以成为全景的视觉中心。而当画面中存在多个物时,将不可避免地分出主要的物和次要的物,次要的物还可以有相对它而言更次要的物。这和此前的基础顺序公式不同,因为基础顺序公式默认一切事物都可以互相叠加——但事实证明不是那样。
无法被叠加的次要物
不难注意到有些“物”像是无视了叠加式构图原则那样,除非权重高到让它占满屏幕,否则往往只能作为配角存在、难以被其它“物”作为叠的目标。这些“物”天生有着被视作次要的特征,和许多能做主能做次的物并不相同。
那么什么因素决定哪些物更倾向于被视为次要呢?终极答案是生活经验。
当 1 girl 和 earring 简单结合时,无论两者谁先谁后,最后都会变成“一个二次元美少女带着耳环”的样子,不会在简短描述下就轻易地出现诸如“美少女向前抬手捧着耳环、耳环在镜头前是一个特写、美少女的身体被景深虚化”的情况。因为在我们的生活常识中,大多数这两个“物”结合的情况都是前者,后者在作品描绘里出现的情况极少,因而这两者即使是顺序调换也只是让美少女是否摆出展示耳环的姿势,无法轻易地切换主次(继续深讲就到训练集的部分了,虽然它的本质是训练集与 LatentDiffusion 对于自然语言的处理,但考虑到大多数组成训练集的作品都取自于生活经验 / 常见创作想象,且自然语言处理本就是努力拟合生活经验的过程,所以实际上并无明显不同,因而在此打住话题)

masterpiece, 1 girl, earring

masterpiece, earring, 1 girl
但当 1 girl 和 lake 结合就不一样了。lake 虽然往往被当做背景,但它完全可以成为风景画的主要描述对象,所以在除去刻意设置了镜头的情况下——当 1 girl 在前,重要的“物”为人物,所以画面往往会让人物占据主要部分(包括人物全身像站在景物前、人物半身像加远景,甚至人物直接泡水),而当 lake 在前,重要的“物”为湖,湖在我们的生活经验中的确可以成为主要对象,因此画面往往会让人物显得更小、更融入风景或距离视角更远。

masterpiece, 1 girl, lake

masterpiece, lake, 1 girl
当“物”的数量大于 2,这个规律也依然适用, 1 girl 和 lake 和 bike 以及 earring 之间的排列组合符合上述情况:earring 总是忽略顺序作为次要装饰在人物的耳边,人物、湖、自行车则根据顺序不同而有不同的强调位置,其中 bike 即使靠后也往往不会过度隐入 lake。

masterpiece, 1 girl, lake, bike, earring
但更重要的是,运用得当的次要物可以一定程度上打破叠加式顺序结构。因为 AI 会努力把所有咒语中的内容都画出来,而次要物们恰好大多数是小块结构。在如第二张图一样的远景中画出让 earring 被 AI 认为是不可能的,所以它会强行打破叠加式结构,让人物被聚焦到画面相对更前的位置,作为对次要物的强调。

masterpiece, lake, earring, bike, 1 girl
lake 在前,但是效果更接近于想象中 lake 在后的情况。在这种强调情况下,甚至 1 girl 在前也无法让它显著地再次提高强调。

masterpiece, lake, 1 girl, earring, bike
无论怎么说,它从原理和实际表现效果都和人有(一点点)相似之处。虽然 AI 绘画看上去是一步成型,但它一定程度上还是会根据“物”与“物”之间的关系来决定构图,并结合场景与反常情况无视部分顺序。
其中“物1、2、3...”是逻辑上能轻易成为主要聚焦点、占据大画面比率的物件,“次要物”则反之。物按照希望的构图主次顺序排列,而将次要物顺序放在其附着对象之后是为了结构简洁明确,也是为了避免超出预期的反常强调。
“次要物”往往都具有能以各种存在形式附着于多种主要物件之上的特性,因此单个主要物的多个次要物按顺序集群排列,有助于避免相对重要的次要物错误绑定的情况。
归根结底,这就是训练集“不平衡”造成的,除非自行训练,不然很难避免这种情况的产生
当然了,再往后我们甚至就可以推导出NAI1.0训练的时候提示词大致的顺序了,这再很多其他模型上是并不适用的,《元素同典》之前是编辑再nai1的时代,很多东西都是围绕nai1这一个模型来研究的。
是结束也是开始
以上内容显然也不是一切的答案,毕竟它标志的是入门而不是大成——本魔导书所详细解释的一切内容都是入门级内容。它更像是对于如何理解 AI 运作方式的思考帮助,而不是能无脑解决所有难题的万用工具,实际操作依然需要更多经验总结来灵活变通。
但仅仅是入门也许并不能满足某些有着雄心壮志、求知欲强的赛博魔法师。赛博魔法似乎无法被穷尽,该如何再次启程呢?
这里不作过多展开,仅留下一些思考线索:
长咏唱能绑定元素,但为什么它的不稳定度反而比其它咏唱方式还高?
分步绘画的画面在分步前后之间有什么关系?
为什么分布绘画能一定程度上“识别”从何处替换物?
每 1 step 在不同完成度下对于 AI 而言到底意味着多大的变化?
不同种子同咒语的镜头为何在绝对意义上频频产生混乱?
叠加式构图中“叠加”的根源是什么?
当一个 prompt 含有多个元素意义时,AI 会如何对颜色、形状等分别处理?
为什么超高步数可以修手?为什么修手一定要那么高的步数?
权重到底意味着什么?数量?画面占比?结构复杂度?
重复输入 prompt 到底意味着什么?
单个单词也会被拆分吗?
......
魔法的殿堂恢宏而瑰丽,无尽的回廊里昭示着无限的可能性。
朝更远处进发吧。
♿ 蚌 埠 感 言 ♿
非常感谢各位的观看,但是非常感谢,总之非常感谢。
前面忘了,中间忘了,后面忘了。
一开始这本魔导书是一位可爱JK的个人经验集,但后来又不知道怎么回事莫名其妙变成了为新人提供从入门到精通的一条路径。又更后来,笔者仔细想了想,世界之大无奇不有,五花八门的技巧总会迭代,我们何德何能敢说读完这一本就算精通啊?所以就变成了从麻瓜到入门()
安装、第一句话、注意事项、技巧补充、公式总结,一切都是那么水到渠成。有许多技术都是随着本魔导书的编写一同被研究而出的,就比如标准顺序公式、分步描绘应用和通用顺序公式。当时笔者还在群内说,通用顺序公式就是入门时期的最强武器了,写完通用顺序公式就结束吧,这个阶段也没什么可写的啦——
结果,就在 2022 年 11 月 2 日晚上 20 点左右,笔者为这魔导书编写感言的时候,关于 emoji 的认知出现了。这确确实实是打乱了一切,我们都绷不住了。紧急加章之后,在“啊差不多得了,这个世界还是毁灭了算了吧”这样的想法之下,我们为这本确实不完全科学的魔导书重新写下了另一版感言——也就是你现在正读到的这一版。
😅 抱歉,流汗黄豆请不要出现,我们讨厌你。
总之,这本魔导书在这里也算是完结了,感谢所有在编写过程中支持笔者的大家。我们下一本典(也许没有)再见!
当然,某种超自然神秘的力量促使我在2年之后的2024重写这一样一本AI绘画提示词的入门文档。那可能是法典组所践行的,“开拓”的意志吧