



该文章由【吐司创造营】直播的部分脚本编成,部分操作向和演示向内容无法用文本撰写,故推荐配合回放观看效果更佳。部分观点来源网络,如有错误欢迎指正!
本期文章对应回放为👉:BV1SA4m1A7kp
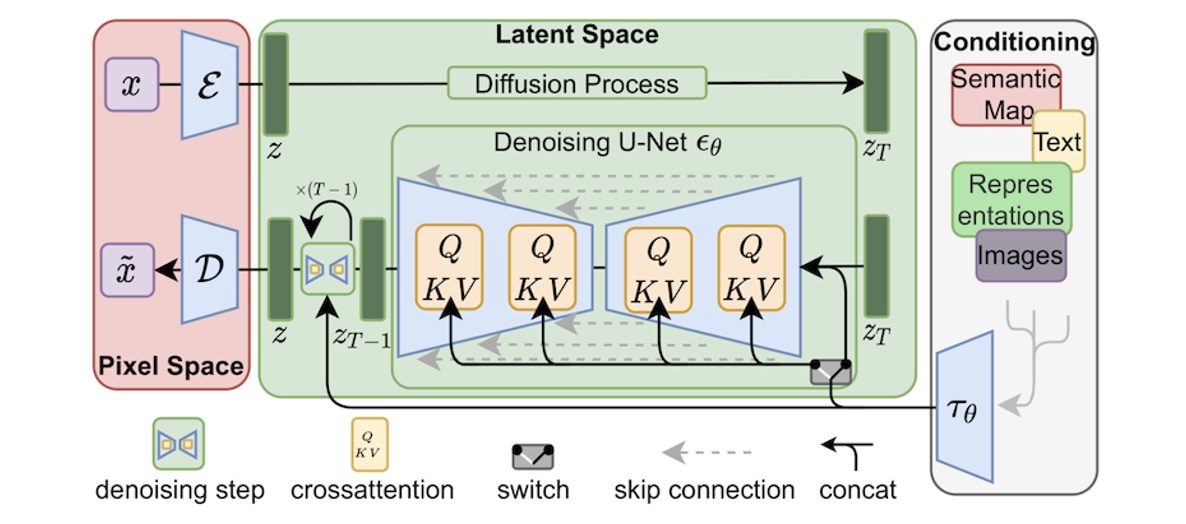
一、 图生图生成原理
有两个非常重要的空间,pixel space 像素空间,和latent space 潜空间,文生图的流程是,先输入提示词,通过clip encoder 就是编码器,转换成sd可以理解的数据传入潜空间,在潜空间中会生成一个随机的噪声,然后通过大模型进行干预,采样器开始降噪,经过几十次的迭代后,生成我们想要的图像,最后通过解码器vae decoder到pixel space像素空间,就是我们能看到的图。
二、吐司通过图生图能实现的效果
那回到我们吐司的工作台来,我们可以通过吐司图生图达到哪些效果呢。
快速抽卡:这里教大家一个如何节省算力快速抽到自己喜欢的卡然后单独进行高清放大的方法,首先我们设置都最低,然后下面的批量数量调整为4,开始低成本抽卡,抽到自己喜欢的之后,再单独选择右上角的高清放大,将它单独送到高清修复里面,然后就可以得到一张比较满意的高清大图。
像素修复:这个比较经典的案例大家可能前段时间经常看到,就是修复一些比较古早的人物角色或者说道具,那我们今天就以修复英雄联盟的游戏装备图标来给大家展示一下图生图的具体用法,期间会用到几个controlnet给大家也做一个预习吧,具体的controlnet的实际应用记得准时来下周的controlnet专题课程。
前期准备:模糊游戏装备图
反推提示词
大模型:ReV Animated
lora:玉器/木雕文玩 0.8
controlNet:无缝拼接——tile_colorfix+sharp
色彩继承——t2ia_color_grid
VAE:vae-ft-mse-840000-ema-pruned.ckpt
高清修复:修复方式:4x-AnimeSharp
重绘噪声强度:0.5
这个方法可以用于各种类似的使用场景,比如说老照片修复。
外部图片放大:如果我有一张sd里的图片,我想在吐司发帖存档怎么办,今天就跟大家传授一下这个小方法。首先还是图生图,这边我们复制一下你在sd里的使用参数然后复制到吐司中来,自动填充了,这里注意一下我们把重绘幅度调整到0.1,基本上不变然后出图,可以看到跟我们的原图差别不大。然后再对这张图片进行单独的高清放大。这张图现在就变成一张可以在吐司发帖的图片了,大家可以发帖然后存在自己的个人账户里。
二转三或者三转二:这个大家在comfy工作流里看的比较多,但其实最基本的webui也可以实现类似的效果,比如说,我想把一个人变成迪士尼风格,只需要调整一下大模型和lora。
三、技术详解
我们第一节课有讲21年到24年3月份的一个ai技术发展时间线,然后我们应该如何选择和利用这些新技术。
首先我们梳理一下基础模型:
SD1.4:官方出的,这个比较少见了,有少数大模型创作者还在更新这个算法的模型,可以忽略。
SD1.5: 官方出的,目前应用最广的基础模型,其基础尺寸为512px,虽然新的技术在不断出现,但估计这个算法还得在一段时间内占据主流。
SD2.0/SD2.1:官方出的,其基础尺寸为768px,剔除了一下NSFW的内容,但是导致人体结构出图效果很差,在SD2.1的时候对该问题进行了修复。
SDXL: 官方出的,逐步占据主导地位,基础尺寸为1024px,其整体图片质量要高于前面3种模型,但生成速度也相对慢不少。
LCM: 清华大学开发的一种可以用更少的采样步数来快速生成图片的技术,但其图片质量要明显比前面基础算法的逊色,目前有少量应用在SD1.5上的模型,不过用在SDXL上的也不算多,因为它刚出来没几天,就有更好用的turbo问世了。
Turbo: 官方出的,主要应用于SDXL基础模型的快速图片生成技术,少见于其它算法,需要的采样步数比LCM还要少,有的模型2步即可生成不错的图片,但其质量也稍逊色于基础的SDXL。
(LCM和Turbo这两个技术的出现象征着ai生图进入实时出图阶段)
Lightning: 字节跳动开发的,截止今日最新的快速出图技术,2-8步即可出图,其整体质量高于LCM和Turbo,估计会逐渐替代两者,但在它流行前会不会出现更好的技术还不好判断,因为AIGC技术的更新速度太快了。
Stable Cascade:官方出的模型,其用法与SD不同,官方声称可以更快的生成更清晰的大图像,但我在使用中并没有感受到它快,图片质量好倒是真的。comfy已有专门用于cascade的节点。
有一个up主做了一个测试,保证输入完全一样的情况下,只切换模型,然后肉眼观察出图质量。这边直接上最后的结果。

LayerDiffusion:是由那个开发出 Controlnet的作者张吕敏,最新推出的一种透明图像生成技术,它的核心所在是“潜在透明度”,即将 Alpha 通道整合到预训练模型的潜在结构中,使模型能够生成带有透明度的图。不仅可以生成一般物体,而且对于玻璃、发光这种透明/半透明的对象,以及头发丝这种精细的内容,生成的效果依旧完美。极大提升了出图效率,而且真正做到了“毫无抠图痕迹”,再也不用担心有白边了。除了直接生成透明底图像,LayerDiffusion 还支持生成分层图像。包括根据一个透明底图像生成完美融合的背景,并将该背景提取为完整独立的图层;以及根据背景图像+提示词生成前景主体,并将该主体提取为透明底图层。


Playground:PlaygroundAI发布的开源模型,官方声称其优于SDXL,1024px的基础尺寸,官方说直出效果比SDXL好,它的使用方法与SDXL一样,有兴趣的同学可以尝试下,抱脸上搜索playground即可,注意需要及时更新comfy才能适配新算法的模型。可能因为没有及时适配的原因暂时无法在webUI中使用。
Pony Diffusion: 一个叫做Pony Diffusion V6 XL的大模型,仅仅上架C站不到半个多月,就获得了1.7万(17k)的下载量,熟悉C站的朋友应该知道,这是个很惊人的数字。Pony用于SDXL的微调,有一些以Pony为基础制作的大模型,多是与Pony Diffusion配合使用,可使用SDXL的VAE,但使用SDXL的Lora效果不一定好。Pony模型需要一些固定提示词,否则出来的图片会很糟糕,在收集Pony模型资料时可以留意下。
作者自己表示:该模型结合了自然语言提示和标签进行训练,能够理解两者,因此大多数情况下使用正常语言描述预期结果是有效的,尽管您可以在主要提示之后添加一些标签以提升它们。该模型在基于作者个人偏好的约 260 万张美学排名的图像上进行训练,动漫/卡通/拟人/小马数据集的比例约为 1:1,安全/可疑/成人评分的比例也是 1:1。 大约 50% 的所有图像都附有高质量详细字幕,这使得自然语言能力非常强大。所有图像都已用字幕(当可用时)和标签进行训练,移除了艺术家姓名,并根据我们的同意/不同意计划过滤了源数据。 已过滤掉涉及未成年角色的任何成人内容。

Stable Video Diffusion:官方的模型,可以用来生成简单的视频。
Stable Zero123: 还是官方的模型,可以为物体生成不同角度的图片,它目前只能针对简单的物体。
大语言模型:
好说完这些我们来看一下大语言模型Grok,马斯克,OpenAI 曾经的联合创始人,更是连夜发布了他新创办的 AI 公司 xAI 的首款产品 Grok。
Grok-1这种方式可以适应多种不同的任务和应用场景,更适合那些想要用开源模型打造自己专有模型的开发者。
技术架构上,和GPT-4一样,Grok-1采用了大规模参数的专家混合模型(Mixture-of-Experts, MoE)架构,可以将大型网络分解为多个“专家”子模块,每个子模块负责处理不同类型的信息或任务。底层技术上,Grok-1选择使用了基于JAX(一个由Google开发的用于高性能机器学习研究的库)和Rust(一种注重安全性和并发的系统编程语言)的自定义训练堆栈。这并不是大型语言模型中常见的选择。大多数知名的大模型比如OpenAI的GPT系列或Google的大模型通常是基于TensorFlow或PyTorch这样的主流深度学习框架开发的,且有丰富的API和社区支持,能让模型开发和训练变得更高效。
优势:
语言更诙谐幽默,更人性化,不那么机器人化。
Grok 支持多个「对话」同时输出,一边写代码一边回答问题,也不在话下,大大提高了用户的工作和娱乐效率。Grok 支持展开多个对话|xAI如果用户对现有的「回答」不满意,还可以展开时间线,直观地导航到不同版本的「回答」,还可以随时切换、修改历史对话记录。这一功能在长对话场景中,具有非常强大的管理优势。
支持超长提示词理解(Super Prompt):可以处理 25k 的 token 的字符。
快速响应:提供即时反馈,可以实现近乎零延迟的交互。
庞大的数据库:目前微调的数据来源是 886.03 GB 版本的「The Pile」数据库,以及整个 X 平台的海量数据。
支持语音输入提示词,输出回复。
「实时」搜索引擎,数据来源优先从 X 上获取。
个性鲜明:搞笑且机智,远离枯燥的「政治正确」。
功能预测
API 功能确定会推出。
未来一定会支持图像生成,图像识别,语音识别等多模态,当前模型已经具备一些相关能力。
轻量版 Grok 将会在特斯拉上实现本地化运行。