新手小白向——吐司模型炼制小攻略
首先:
打开吐司官网(https://tusiart.com/)进入模型训练界面:
第二步:
上传训练数据集,最好是准备好事先裁剪好的素材(素材分辨率最好是64的倍数),上传然后打标;
打标方式:
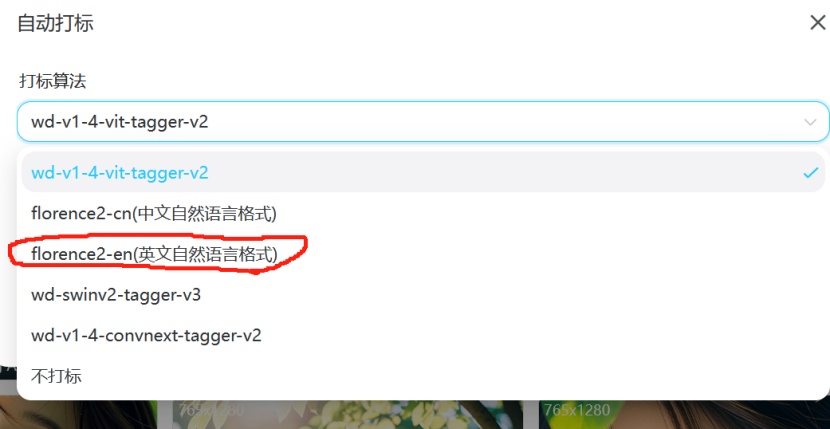
Flux的模型训练推荐使用自然语言英文打标;其他sd1.0或者1.5的底膜使用wd1.4的打标模型打标即可;
真人模型推荐用自然语言,二次元推荐用wd1.4;
第三步:
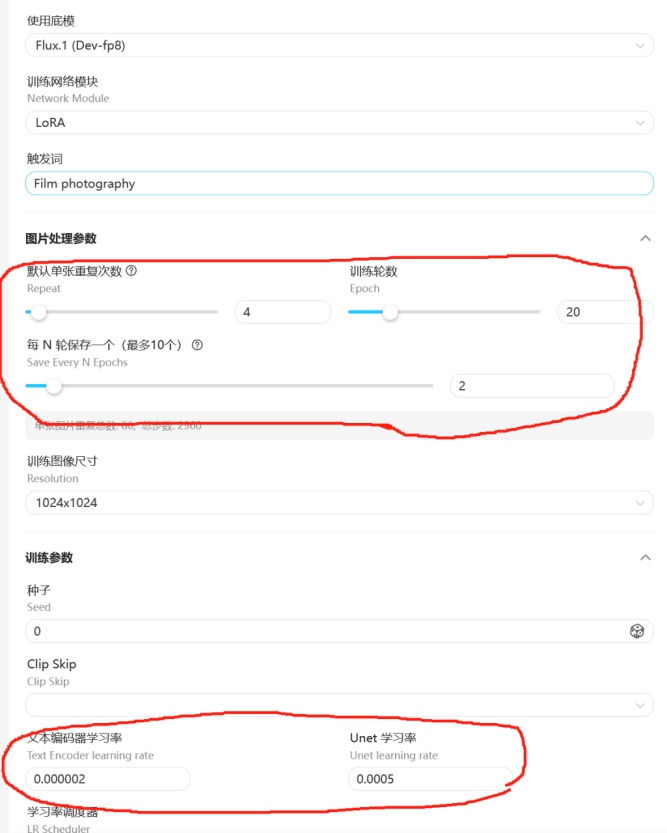
主要参数设置:
单张重复次数(Repeat)代表训练一轮模型学习这张图片的次数,
训练轮数(Epoch)代表,训练的总轮次,
一般(Repeat)乘以(Epoch)达到100以上就有一个比较好的模型训练成果。
两者相乘再乘以上传数据集的图片数量就等于总训练步数。
接下来要设置的是:
文本编码器学习率
Text Encoder learning rate
以F1的底膜为例,一般设置为:2e-6
Unet 学习率
Unet learning rate
以F1的底膜为例,一般设置为:5e-4
或者直接采用系统推荐的学习率参数
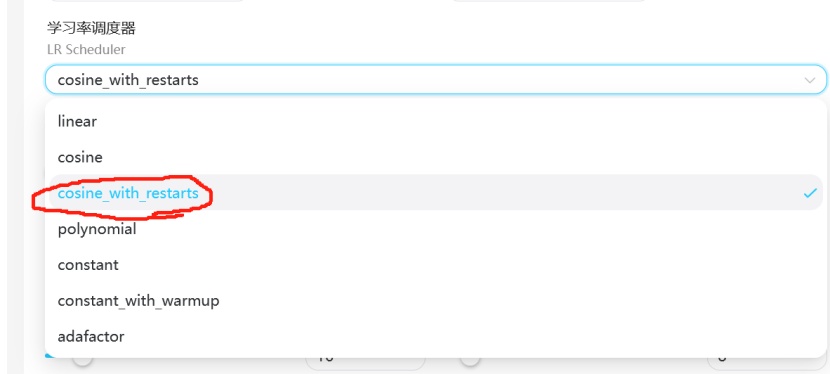
学习调度器选择:
优化器选择:
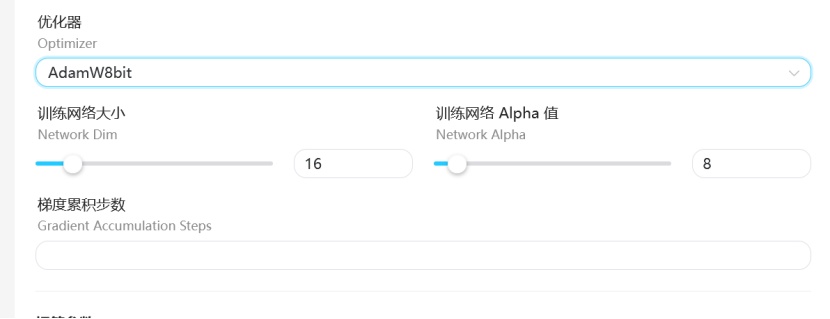
训练网格大小和alpha值设置:
这两者决定了你训练出来的模型的文件大小,以F1的底膜为例,一般数据集比较小时设置成16-8,或者是32-16就可以,前者保持在后者的2倍,数值设置越大训练的速度越慢,相对来说学习深度越高。
最后设置样图的大小和样图提示词:
噪声偏移及其他几种高级参数对F1的lora训练影响不大,保持默认值或者改成0都可。
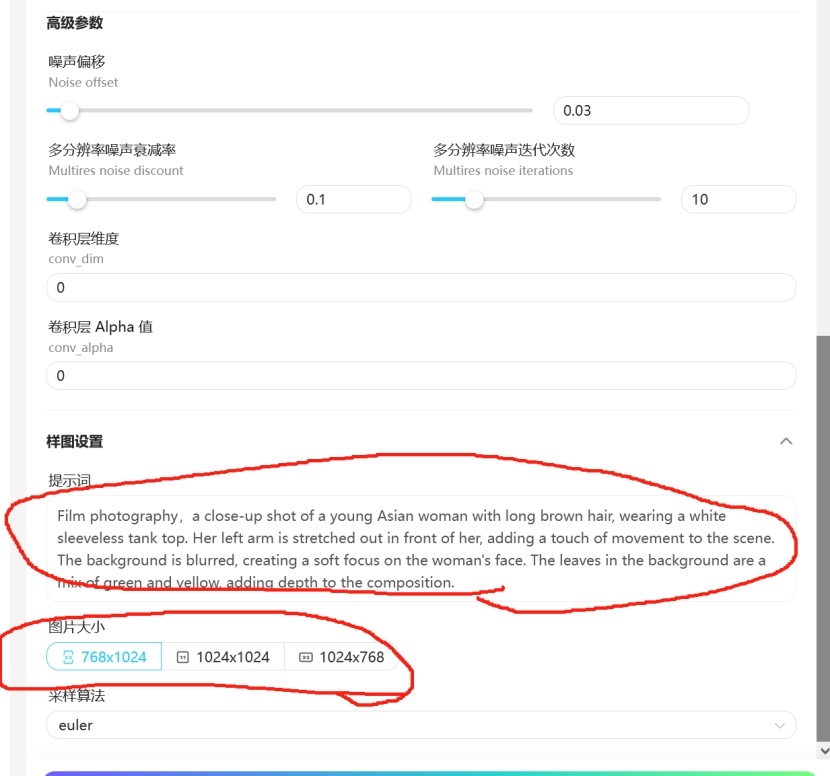
别忘了添加你的触发词:
使用批量加标签加入触发词
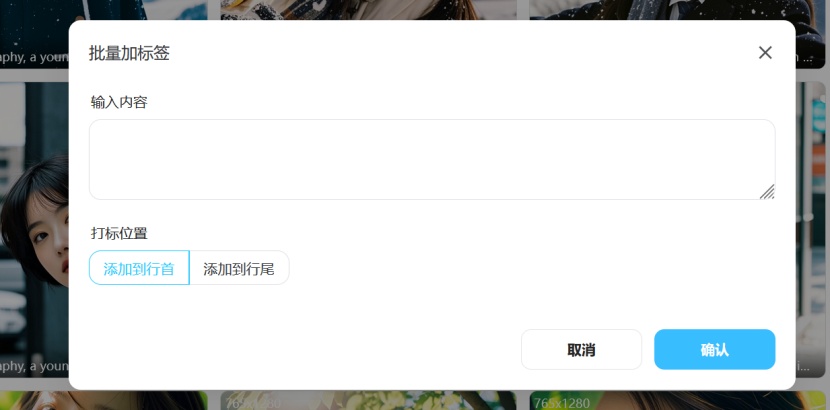
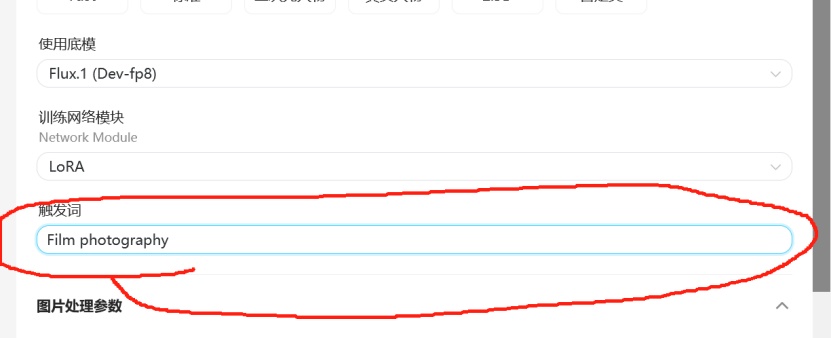
第三步:
点击立即训练:完成你的lora训练吧!
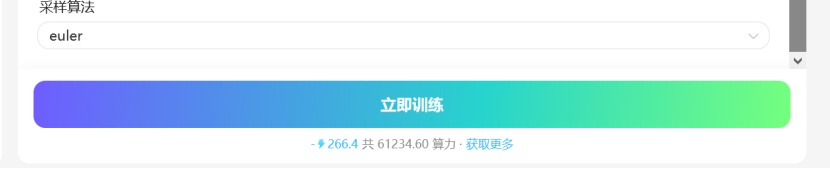
第四步:
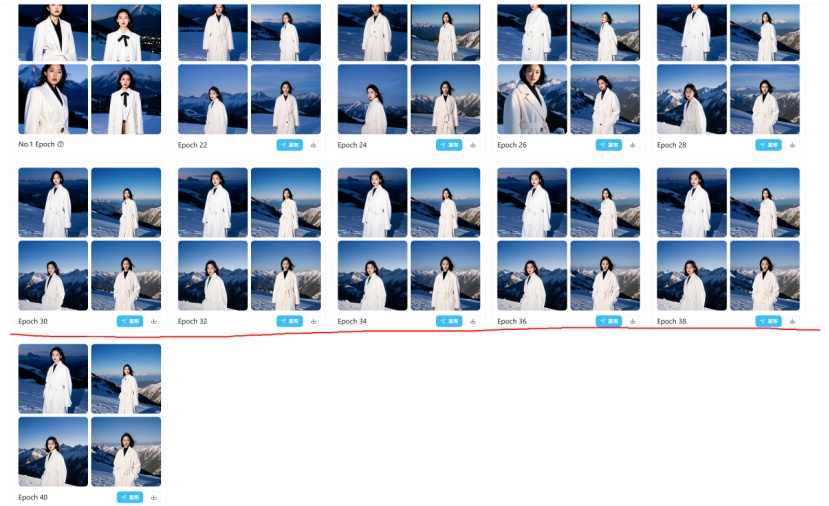
训练完成后选择符合你要求的模型,吐司可以保存十个不同轮次的模型,从中挑选出你喜欢的。
通过查看loss值看模型的拟合程度: