【炼丹笔记】提高batch size对训练lora真的有用吗?
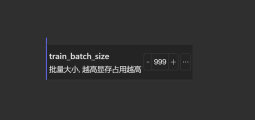
阅前提示:本文远非专业论文,仅为个人学习过程的记录,仅供个人学习使用。本文所有内容均没有科学理论支撑,请谨慎甄别。我已经不止一次听到“batch size建议开大一点”的说法了。目前的主流观点,batch size似乎是根据显卡的性能决定的,显存越大,batch size就能开得越大,就好像batch size越大越好一样。真的是这样吗?理论上说,batch size是模型训练时同时学习的图片数量,增大batch size可以加快模型的拟合。但是,加快了学习速率之后,难道就不会对学习效果产生影响吗?我之前训练过《喜羊羊与灰太狼》中的若干角色的Lora模型(只不过都是私模,不开源)。我比较习惯的训练方法是,找70张左右的图片,repeat设为6,batch size设为1。学习率是这样确定的,优化器先用DAdaptation,训练1个epoch,找到合适的学习率大小,然后把这个值除以3,填入学习率中,并把优化器改为Lion,调度器改为cosine with restarts,把文本编码器的学习率设为unet学习率的1/10。训练8个epoch左右,即3000步左右,最后出xy图表做挑选。别问我为什么这样练,问就是从各种地方看到的经验加我自己的经验。在训练沸羊羊的模型的时候,我就尝试过把batch size从1调到2,发现拟合效果明显变好了(详见:【AI绘画沸羊羊_V1.5】SD1.5 Lora炼丹笔记- 哔哩哔哩(bilibili.com))。但是,同样的方法在喜羊羊的模型和灰太狼的模型上却没有明显的效果,如下图:喜羊羊batch size=1横轴为epoch,纵轴为模型权重,下同。喜羊羊batch size=2灰太狼batch size=1灰太狼batch size=2喜羊羊和灰太狼的模型拟合效果不佳应该是训练集的问题。要想训练喜羊羊这种非人类Q版动漫角色,难度肯定是比训练人类角色更大的,所以它对训练集的要求会比较高。在动漫中,经常会出现这些角色打斗的画面,那些动画师们(比如这次即将在7月19日上映的《喜羊羊与灰太狼》大电影9《守护》的总导演黄俊铭和陈力进,这里我夹带私货做个广告,这次似乎是机战主题,推荐大学生去看看)在画打戏时会画出很多姿势奇怪、身体变形、透视夸张的镜头,以加强画面张力。而我在做训练集时没有刻意回避这些镜头,因而影响了模型训练。在训练集的影响之下,batch size的影响微乎其微。到目前为止,我这里质量最好的是美羊羊的训练集(可能是因为美爷的打戏不多?),所以,接下来以美羊羊的Lora模型为例,探究一下batch size增大时,模型的还原度和泛化性到底是不是更好了。这里的还原度是指把角色画准确的能力,这里的泛化性是指画出训练集中没有的场景的能力。我对模型的评价方式为,用我的肉眼主观观察出图效果,原因有二:这是最直接的评价方式;我不懂类似CCIP那样的评判方式,不知道哪些比较适合。出图参数如下:Prompt: masterpiece, best quality, high detail, highres, 1girl, Tibbie, sheep, full body, looking at viewer, <lora:Tibbie1-000001:0>Negative prompt: lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, overlapping, disfigured, uglySteps: 20, Sampler: DPM++ 2M, Schedule type: Karras, CFG scale: 7, Seed: 29464874, Size: 512x512, Model hash: 7c348e096a, Model: cuteyukimixAdorable_neochapter3, VAE hash: ****45af8d, VAE: animevae.pt, Clip skip: 2, Lora hashes: "Tibbie1-000001: 23ee3414dfc1", Script: X/Y/Z plot, X Type: Prompt S/R, X Values: "01,02,03,04,05,06,07,08", Y Type: Prompt S/R, Y Values: ":0,:0.3,:0.5,:0.6,:0.7,:0.8,:0.9,:1", Version: v1.9.3出图结果如下:batch size=1batch size=2batch size=3batch size=4batch size从1提升到2之后,模型会更容易在较低权重下画出美羊羊的特征,且在较高权重下能比原来画得更像。也就是说,还原度确实有所提升。但是,batch size提升至3以上之后,就没有明显的优势了,甚至还原度反而不如batch size=2的时候。接下来画一些训练集中没有的场景,“坐在树上”:Prompt: masterpiece, best quality, high detail, highres, 1girl, Tibbie, sheep, <lora:Tibbie1-000001:0>, sitting on tree, looking at viewerNegative prompt: lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, overlapping, disfigured, uglySteps: 20, Sampler: DPM++ 2M, Schedule type: Karras, CFG scale: 7, Seed: 487059718, Size: 512x512, Model hash: 7c348e096a, Model: cuteyukimixAdorable_neochapter3, VAE hash: ****45af8d, VAE: animevae.pt, Clip skip: 2, Lora hashes: "Tibbie1-000001: 23ee3414dfc1", Script: X/Y/Z plot, X Type: Prompt S/R, X Values: "01,02,03,04,05,06,07,08", Y Type: Prompt S/R, Y Values: ":0,:0.3,:0.5,:0.6,:0.7,:0.8,:0.9,:1", Version: v1.9.3batch size=1batch size=2batch size=3batch size=4我们来看看树干是什么时候消失的。batch size=1时,模型权重达到0.8时,树干就开始变成石头或土地了。batch size=2时,模型权重达到0.8时依然能完好地画出树干的形态,第8个epoch的模型在权重为0.9时依然能表现出树桩的木纹肌理。batch size=3时,只有第8、14、15个epoch的模型把树干保留到了0.8的权重。batch size=4时,权重才0.7,树干就已经消失或覆上一层草地一样的青苔了。batch size为2时为泛化性最优情况,batch size更大时反而不如为1的时候。也许,“坐在树上”对于模型来说太简单了,让我们试试“躺在沙滩上”:Prompt: masterpiece, best quality, high detail, highres, 1girl lying on beach, Tibbie, sheep, full body, <lora:Tibbie1-000001:0>Negative prompt: lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, overlapping, disfigured, uglySteps: 20, Sampler: DPM++ 2M, Schedule type: Karras, CFG scale: 7, Seed: 1680887032, Size: 512x512, Model hash: 7c348e096a, Model: cuteyukimixAdorable_neochapter3, VAE hash: ****45af8d, VAE: animevae.pt, Clip skip: 2, Lora hashes: "Tibbie1-000001: 23ee3414dfc1", Script: X/Y/Z plot, X Type: Prompt S/R, X Values: "01,02,03,04,05,06,07,08", Y Type: Prompt S/R, Y Values: ":0,:0.3,:0.5,:0.6,:0.7,:0.8,:0.9,:1", Version: v1.9.3batch size=1batch size=2batch size=3batch size=4在这里,沙滩床是我在提示词中没有提到,大模型自己发挥的内容,所以沙滩床的消失不能用于评判模型泛化性。我们主要还是看看躺着(趴着也是lie)的姿势的崩坏程度。batch size=1时,较准确的美羊羊形象到0.7的权重时才出现,权重增加到1之后,美羊羊直接就只剩一个头了。batch size=2时,权重0.5时就能画出较准确的美羊羊趴在沙滩上的形象,尽管权重超过0.8后美羊羊坐起来了,没有严格地遵循提示词。batch size=3时,到了0.7的权重才出现美羊羊的形象,并且成功地将提示词中的动作描述保持到了最后,但是崩坏一直很严重。batch size=4时,沙滩床倒是神奇般地保留到了最后,美羊羊的形象也在0.6的权重时出现了,而且也一直保持着提示词中的动作描述,但是依然有较严重的崩坏。故而,batch size的最优值依然是2。看上去,batch size提得太高了之后,lora对提示词的理解会更好,但是主体物的训练效果也会打折扣。这可能是因为我训练的角色的特殊性,可能只能让模型慢慢学习才能获得良好的效果。总结一下,对于角色lora的训练来说,最重要的依然是训练集(包括图片和标签)。在较优质的训练集下,适量增大batch size有助于提升模型的质量,故训练时增大batch size是值得尝试的。但是,batch size不宜过大。有些角色,由于其复杂性,可能不适合过快的拟合速度,用较低的batch size缓慢拟合会更好。